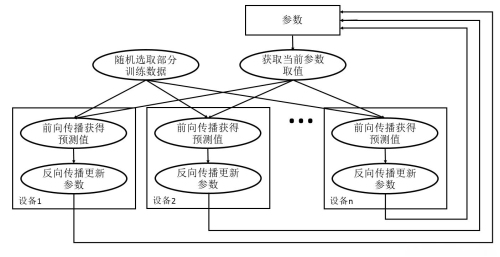
在云计算环境中,处理数据一致性问题是一个复杂而关键的任务,涉及多个方面和策略。以下是一些主要的方法和步骤,用于解决云计算中的数据一致性问题:
1. 了解一致性模型
首先,需要理解不同的一致性模型,包括强一致性、弱一致性和最终一致性。这些模型描述了分布式系统中数据在不同节点间的同步程度和可见性。
强一致性:要求任何时刻所有节点上的数据都是一致的。这通常通过同步复制和分布式事务等技术实现,但可能带来较高的延迟和性能开销。
弱一致性:允许系统在一定时间内存在数据不一致,但最终会趋于一致。这种模型适用于对实时性要求不高的场景。
最终一致性:是弱一致性的一种特例,它保证在没有新的更新操作的情况下,系统最终会达到一致状态。这是分布式系统中常用的一致性模型。
2. 选择合适的一致性算法
根据系统的需求和特性,选择合适的一致性算法来确保数据的一致性。常见的一致性算法包括Paxos、Raft和Zab等。
Paxos:一种用于实现强一致性的一致性算法,通过多轮投票和选举来实现节点之间的一致性。
Raft:一种用于实现最终一致性的一致性算法,通过领导者(Leader)和追随者(Follower)的机制来确保数据的一致性。
Zab:也是一种用于实现强一致性的一致性算法,同样依赖于领导者(Leader)和追随者(Follower)的机制。
3. 实施数据复制策略
数据复制是实现数据一致性的重要手段。通过在不同节点上复制数据,可以提高数据的可用性和容错性。
主备复制:一种常见的数据复制策略,其中一个节点(主节点)负责写入数据,而其他节点(从节点)复制主节点的数据。这可以确保数据的一致性,但可能会引入延迟。
同步复制与异步复制:同步复制要求在所有节点都确认写入操作后才能认为操作成功,而异步复制则允许在单个节点上写入后立即返回成功,其他节点的复制操作在后台进行。
4. 使用分布式事务
分布式事务是在多个节点上执行的一个原子性操作,可以确保跨多个节点的数据操作的一致性和完整性。常见的分布式事务协议包括两阶段提交(2PC)和三阶段提交(3PC)等。
5. 引入版本控制和时间戳
为每个数据操作分配一个唯一的版本号或时间戳,可以确保在同一时间内只有一个操作能够拥有最新的版本号或成功执行。这种方法有助于解决数据冲突和并发问题。
6. 采用基于事件的同步
基于事件的同步是一种解耦的同步方式,每个节点将事件发布到一个中心消息队列,其他节点订阅并处理这些事件。这种方式可以降低节点间的耦合度,但可能需要额外的机制来确保事件的顺序性和一致性。
7. 建立监控和告警系统
实施全面的数据一致性监控和告警系统,实时监测数据状态并发现潜在的不一致问题。通过设置阈值和告警规则,可以及时通知管理员进行处理和修复。
8. 定期备份和恢复
建立完善的数据备份和恢复机制,确保在数据丢失或损坏时能够及时恢复。通过定期备份、增量备份或快照技术,可以保障数据的可靠性和完整性。
处理云计算中的数据一致性问题需要综合考虑多种因素和方法。根据系统的具体需求和特性,选择合适的一致性模型、算法、复制策略、事务处理机制以及监控和恢复措施,可以有效地提高数据的一致性和可靠性。