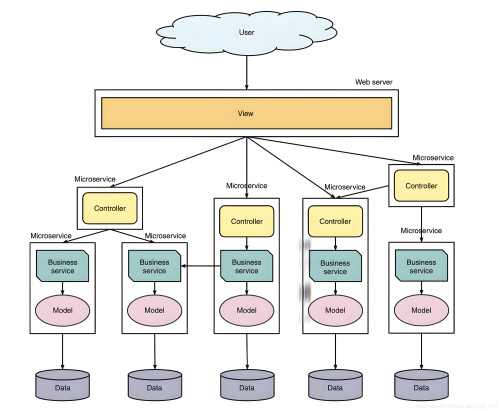
在爬虫开发过程中,数据抓取是第一步,但抓取到的数据往往需要进行持久化存储,方便后续分析和使用。存储方式可以根据需求选择不同的存储介质,如数据库、文件(JSON、CSV、XML)、甚至是云存储。Scrapy框架内置了数据存储管道(Item
Pipeline)机制,可以方便地将抓取到的数据存储到各种介质中。
本文将介绍几种常见的持久化存储方式,并说明如何在Scrapy中实现数据持久化存储。
一、使用Scrapy的管道(Item Pipeline)进行数据持久化
Scrapy的管道(Item Pipeline)功能允许你在抓取到的数据(Item)被提取后,进行一系列的处理,并最终存储。你可以在管道中将数据保存到文件、数据库、甚至进行数据清洗和去重等操作。
Scrapy中的管道有一个简单的工作流程:
每个爬虫抓取到的Item会依次传递到管道。
管道对数据进行处理(如清洗、验证等)。
处理后的数据会被保存到所选择的存储介质中。
基本配置
首先,在项目的settings.py文件中启用管道:
pythonCopy CodeITEM_PIPELINES = {
'myproject.pipelines.JsonPipeline': 1, # 优先级1,执行顺序越高越优先
'myproject.pipelines.MongoDBPipeline': 2,
}

二、常见的存储方式
1. 存储到JSON文件
JSON格式存储非常适合结构化数据,易于处理和分享。Scrapy提供了内置的支持,可以直接将抓取的数据保存为JSON文件。
示例:将数据存储为JSON文件
首先,创建一个管道,将抓取的Item保存为JSON格式:
pythonCopy Codeimport json
class JsonPipeline:
def open_spider(self, spider):
self.file = open('output.json', 'w', encoding='utf-8')
self.writer = json.JSONEncoder(indent=4, ensure_ascii=False)
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
# 将每个Item转换为JSON格式并写入文件
json_data = self.writer.encode(item)
self.file.write(json_data + '\n')
return item
该管道实现了以下功能:
open_spider:在爬虫启动时打开文件。
close_spider:在爬虫结束时关闭文件。
process_item:将每个抓取到的Item转换为JSON格式并写入文件。
2. 存储到MongoDB数据库
对于数据量较大且需要频繁查询的应用,MongoDB等NoSQL数据库非常适合存储。我们可以利用pymongo库将数据持久化到MongoDB中。
示例:将数据存储到MongoDB
首先,安装pymongo库:
bashCopy Codepip install pymongo
然后,创建一个管道,将抓取的数据保存到MongoDB数据库中:
pythonCopy Codeimport pymongo
class MongoDBPipeline:
def open_spider(self, spider):
# 建立与MongoDB的连接
self.client = pymongo.MongoClient('localhost', 27017)
self.db = self.client['mydatabase']
self.collection = self.db['quotes']
def close_spider(self, spider):
# 关闭MongoDB连接
self.client.close()
def process_item(self, item, spider):
# 将数据存入MongoDB集合
self.collection.insert_one(dict(item)) # 将Item转换为字典后存储
return item
管道工作原理:
open_spider:在爬虫启动时与MongoDB建立连接,并选择数据库和集合。
close_spider:在爬虫结束时关闭数据库连接。
process_item:将抓取到的Item转换为字典格式,并将其插入到MongoDB的指定集合中。
3. 存储到MySQL数据库
对于关系型数据,MySQL是一个常见的选择。在爬虫中使用MySQL存储数据时,我们可以利用pymysql库将数据插入到数据库。
示例:将数据存储到MySQL
首先,安装pymysql库:
bashCopy Codepip install pymysql
然后,创建一个管道,将抓取的数据保存到MySQL数据库中:
pythonCopy Codeimport pymysql
class MySQLPipeline:
def open_spider(self, spider):
# 与MySQL建立连接
self.conn = pymysql.connect(
host='localhost',
user='root',
password='password',
database='quotes_db',
charset='utf8mb4'
)
self.cursor = self.conn.cursor()
def close_spider(self, spider):
# 关闭数据库连接
self.conn.commit()
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
# 将数据插入到MySQL数据库
sql = "INSERT INTO quotes (text, author, tags) VALUES (%s, %s, %s)"
values = (item['text'], item['author'], ','.join(item['tags']))
self.cursor.execute(sql, values)
return item
在此管道中:
open_spider:在爬虫启动时建立MySQL数据库的连接。
close_spider:在爬虫结束时提交事务并关闭连接。
process_item:将抓取到的名言数据插入到quotes表中。
三、存储到其他存储介质
除了JSON、MongoDB和MySQL,Scrapy还支持将数据存储到其他存储介质,例如:
CSV文件:通过csv模块可以将数据存储为CSV格式。
SQLite数据库:使用SQLite存储轻量级的结构化数据。
Elasticsearch:用于大规模分布式搜索和分析。
每种存储介质的操作逻辑都类似,可以通过Scrapy的管道进行处理,只需修改process_item方法即可。
四、使用Scrapy提供的默认存储方式
Scrapy内置了对文件(如JSON、CSV、XML)和数据库(如MongoDB、SQLite)等多种格式的支持。如果不需要自定义管道,Scrapy本身已经可以通过命令行参数轻松实现数据持久化。
例如,将抓取数据保存为JSON格式:
bashCopy Codescrapy crawl quotes -o quotes.json
此时,Scrapy会自动将抓取到的数据存储到quotes.json文件中。
持久化存储是爬虫开发中的重要环节,通过合适的存储方式,可以确保抓取到的数据长期保存,并且便于后续分析和处理。Scrapy的管道机制使得数据存储变得非常灵活,支持多种存储介质(如文件、数据库、云存储等),并且可以根据需求定制存储逻辑。
在实际开发中,选择存储方式应根据数据量、查询频率、数据结构等因素来决定。无论选择哪种方式,Scrapy都提供了非常便利的工具来实现高效的数据存储。